I suggested at the outset, that you can catalog and index data using Ila instead of another database. Let us explore how link awareness can be exploited this way.
Suppose we wish to compile a catalog of all known HTTP servers on the web using Ila. We would like to organize the catalog in such a way that we can list HTTP servers with certain attributes. For example, we would like to be able to list the HTTP servers by the type of operating system it runs on, by the type of web server (e.g. IIS, Apache), and so on. For any given web server, this information is available from one or more of the HTTP response headers. For example:
Server: Apache/1.3.23 (Unix) (Red-Hat/Linux) tomcat/1.0 mod_ssl/2.8.7
A conventional approach to compiling this catalog might involve parsing the above header for the root document of each HTTP server and then storing the data in a table on a relational database. The primary column of the table would contain the name of the server, another would contain the operating system, and still another would contain the name of the HTTP software module. To list all known web servers running under Linux, then, we would perform the following SQL query:
SELECT host FROM http_servers WHERE os='Linux';
In practice, in order to make this a fast search, we would index the os column of the http_servers table; in order to make it user-friendly, we would present this information through a web page that performs the SQL query on the user's behalf.
A link aware strategy for compiling this catalog, however, involves much less backend work: it consists of encoding the information in web documents and then registering the URLs of those documents with Ila (or a competing link database). The URLs of these documents are designed to indicate the type of information encoded in them.
Specifically, we arrange to represent any given HTTP server with a web page that contains links to various "attribute" pages depending on the values parsed in the response header above. We'll call these web pages (see the blue-ribboned documents in Figure 2.8) host meta pages. Host meta pages are generated dynamically using the output of the HTTP servers they represent.
Consider the fictitious HTTP server at www.abc.biz. Meta information about this server is generated dynamically and exposed through the URL http://hostquest.org/host/www.abc.biz as follows:
- Our server-side script retrieves the root document of www.abc.biz and parses the HTTP Server header field in order to determine the operating system for the www.abc.biz host machine and the name of the HTTP software running on it. It is an iPlanet web server running on HP-UX.
- Our server-side script outputs an HTML document containing a link to http://hostquest.org/os/hp-ux and another link to http://hostquest.org/httpd/iplanet. The web page http://hostquest.org/so/hp-ux) represents the HP-UX operating system and the link to it from our generated page means that www.abc.biz runs on HP-UX. Similary, the web page at http://hostquest.org/httpd/iplanet represents the iPlanet HTTP software program.
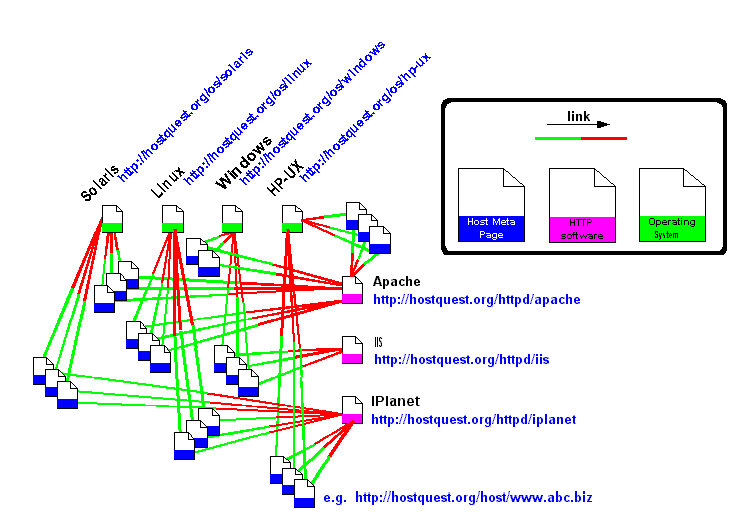
To list all web sites running on Apache, a user queries Ila for backlinks from http://hostquest.org/httpd/apache; to list web sites running under Linux, a user queries Ila for the backlinks of http://hostquest.org/httpd/apache. Moreover, since the backlinks returned by Ila are lexicographically ordered, a user can compute the intersection of the above two lists quickly: that is, a user can quickly compute a lexicographically ordered list of web sites hosted on the Linux operating system and running on the Apache web server.
Note
Generally, because all Ila entries (and their links) are indexed by their URIs, their unions and intersections can be computed quickly.Put some closing remarks here...