An Ila client can see a plan view of any web locality. Moreover, the client can choose to filter the linked resources somewhat according to their ownership. In Ila, URIs are hierarchically ordered, and the hierarchy of any given URI conveys a sense of who owns it. (More on the semantics of this ownership hierarchy, later.)
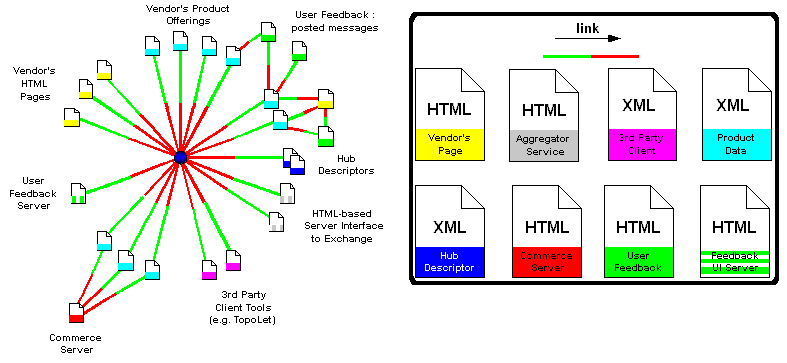
Consider Figure 2.7, a view of a fictitious link neighborhood (web locality). Here, the blue node is the central document (the hub) about which this particular view of the link neighborhood is organized. This central document represents a topic (the figure above suggests the topic is a product, or category of product). Link aware users explore this web locality by navigating the topic's backlinks. These backlinks lead to a variety of web resources authored and published by a plurality of individuals and organizations. Some in this web locality are vendors (represented by the yellow-ribboned documents) that specialize in selling the product (or products). Others specialize in providing an interface through which users can submit feedback about the vendors (green-ribboned documents): these user-authored documents link to the vendor pages they are commenting about. Another web site (grey-ribboned), specializes in presenting an HTML view of this web locality that aggregates and packages the information in this link neighborhood: the web site advertises the existence of this view by annotating the hub with a document suitably describing the view that it provides. Other web sites, still, (see the fuchsia-colored documents) provide executable code and perhaps link-search algorithms that may be applied to this web locality. All these specialists, advertise their existence through the semantics of linking to the topic node or other nodes in the link-vicinity of the topic.
The point of Figure 2.7 is not to provide a blueprint about how content ought to be organized; rather, it is to suggest how information can and may be organized for a link aware audience. A distinguishing feature of organizing information this way, is that no one entity is in control of the whole. That is, a web locality has no final arbiter of acceptable conduct and best practices. Rather, because link aware users can filter out arbitrary URL patterns from the backlinks they examine and explore, it is in a publisher's interest to link judiciously and purposefully, to clearly spell out (in English, and other natural languages) the semantics of their linking -- perhaps to the point of branding it -- so that users learn what type of content to find and expect when they navigate a backlink from the hub (topic) document to a document with a branded URL pattern.
For example, if the "user-feedback provider" in Figure 2.7 (represented by the green-ribboned documents) is administered under the domain name talkback.biz, and all user-submitted commentary is posted to the users.talkback.biz web server, then it behooves the managers of talkback.biz to adopt a URL naming scheme that allows a link aware user to retrieve and explore just positive comments or negative comments by searching for backlinks with a particular URL lexical pattern. The lexical pattern of talkback.biz's URLs might be organized as follows:
http://users.talkback.biz/submissions/?score=[..]&id=[..] . This pattern denotes web pages containing user-submitted feedback. These pages link to, and thereby annotate, the resources they comment on. The score=[..] name/value pair is the score the user gave to the web page they were commenting on with 0 (zero) denoting the lowest score, and 9, the highest possible score. Link aware users interested in exploring just positive comments about a given vendor, search for documents in the lexical range http://users.talkback.biz /submissions/?score=5* to http://users.talkback.biz/submissions/?score=9* that reference (link to) a given vendor page; to find negative comments, they search for URLs in the lexical range http://users.talkback.biz/submissions/?score=0* to http://users.talkback.biz/submissions/?score=4*.
http://users.talkback.biz/aggregates/?ag_score=[..]&ag_id[..] . This pattern denotes web pages encapsulating aggregate scores computed from a plurality of the user-feedback pages, discussed above. As before, this score aggregation page links to the resource that users have submitted scores and commentary on. Link aware users interested in exploring aggregate scores for user submitted feedback on any particular vendor, search and explore backlinks of the form http://users.talkback.biz/aggregates/.
This link-based publishing strategy allows information to be published and discovered through a neutral linking semantic. It is simple, human-readable, and practicable. Most importantly, it is not an overspecified semantic like many an XML specification that I have run across. Its loose structure is its strength. Links designed for link aware audiences allow new information to be positioned and juxtaposed against the old.
How to find the new information, given that we know the old. That, perhaps, is the central idea behind what I call link awareness. For once we have adopted this link aware infrastructure, the information conduit, the backlink establishing a path from the old to the new, from the past into the present, we will have established a more fluid, organic, evolutionary information ecosystem.
Our information ecosystem has always been organic. And the web has made it only more so. The web itself is a big, organic mess. As it has to be. After all, it is not pure machine. For as long we are behind the wheel, the web will continue to be an extension, an image, of ourselves, the messy, unstructured beings that we are. As engineers, we want to bring order to this chaos. As we should: that's one of the functions of our job.
The web is a quilt: a mosaic patchwork of plain, human readable, loosely structured HTML text. This HTML is ostensibly a presentation-layer document format: the actual information content, it is argued, is not contained in the markup, but in the natural language text that permeats its markup elements. Now this natural language content is not machine-readable. As programmers, we want to make the web machine-readable. To do so, some are proposing we trade away the relative syntactic freedom of our natural languages for the strict, syntactic determinism of an XML specification. While machine-readablility is a laudable goal, however, we should not lose sight of the fact that the web owes much of its success to (i) the loose coupling of its component parts, and (ii) the almost artistic freedom if affords its authors. That is, a strategy aimed at making the web more structured will likely fail if it is specified to the point that it constricts an author's expressive power, if it tightly couples collaboratively authored content, or if it attempts to transform the web's connectivity graph into a giant directory tree.
The main advantage of our link aware approach is that it is not an over-specification; rather it is a natural, logical extension of the existing structure. If inferring semantic structure from the topology of links in HTML (ostensibly a persentation format) does not sit well with you, or if you feel there is something fundamentally wrong with encoding semantic content in URL strings then perhaps the following observations will help allay your concerns:
- HTML is not a pure presentation-layer format. It is already peppered with meta-informational components (such as for example the link element) that properly fall outside the purview of presentation mark up. In a similar vein, an HTML document's hyperlinks can be considered logical components of its content that are exposed through the view.
- There is nothing that marries our linking semantic to HTML per se: any format supporting a referencing mechanism to a URI is generally workable. From Ila's perspective, the semantics of linking are independent of the document format.
- You can think of a URL not just as a resource locator, but also as an index onto a resource. In fact, the existing HTTP infrastructure supports this view: a given resource may be "located" from multiple URLs. In order to index a resource in a particular way, it is perfectly fine to expose (or otherwise identify) the same resource under one or more names (URLs).